简介
布隆过滤器(BloomFilter)是一种用于判断元素是否存在的方式,它的空间成本非常小,速度也很快。
但是由于它是基于概率的,因此它存在一定的误判率,它的Contains()操作如果返回true只是表示元素可能存在集合内,返回false则表示元素一定不存在集合内。因此适合用于能够容忍一定误判元素存在集合内的场景,比如缓存。
它一秒能够进行上百万次操作(主要取决于哈希函数的速度),并且1亿数据在误判率1%的情况下,只需要114MB内存。
原理
数据结构
布隆过滤器的数据结构是一个位向量,也就是一个由0、1所组成的向量(下面是一个初始向量):

添加
每个元素添加进布隆过滤器前,都会经过多个不同的哈希函数,计算出不同的哈希值,然后映射到位向量上,也就是对应的位上面置1:
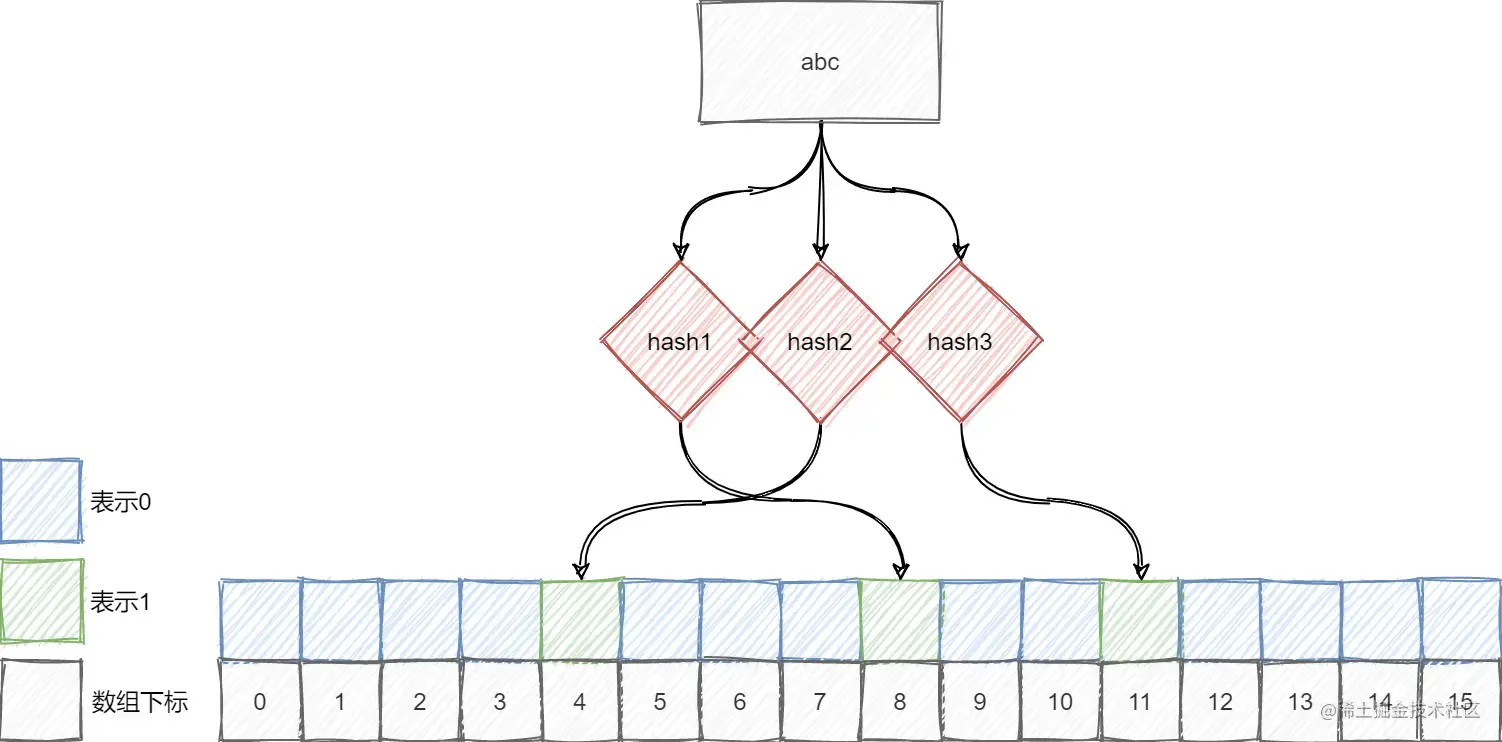
判断存在
判断元素是否存在也是如上图流程,根据哈希函数映射的位置,判断所有映射位置是否都为1,如果是则元素可能存在,否则元素一定不存在。
由于不同的值通过哈希函数之后可能会映射到相同的位置,因此如果一个不存在的元素对应地位位置都被其他元素所设置位1,则查询时就会误判:
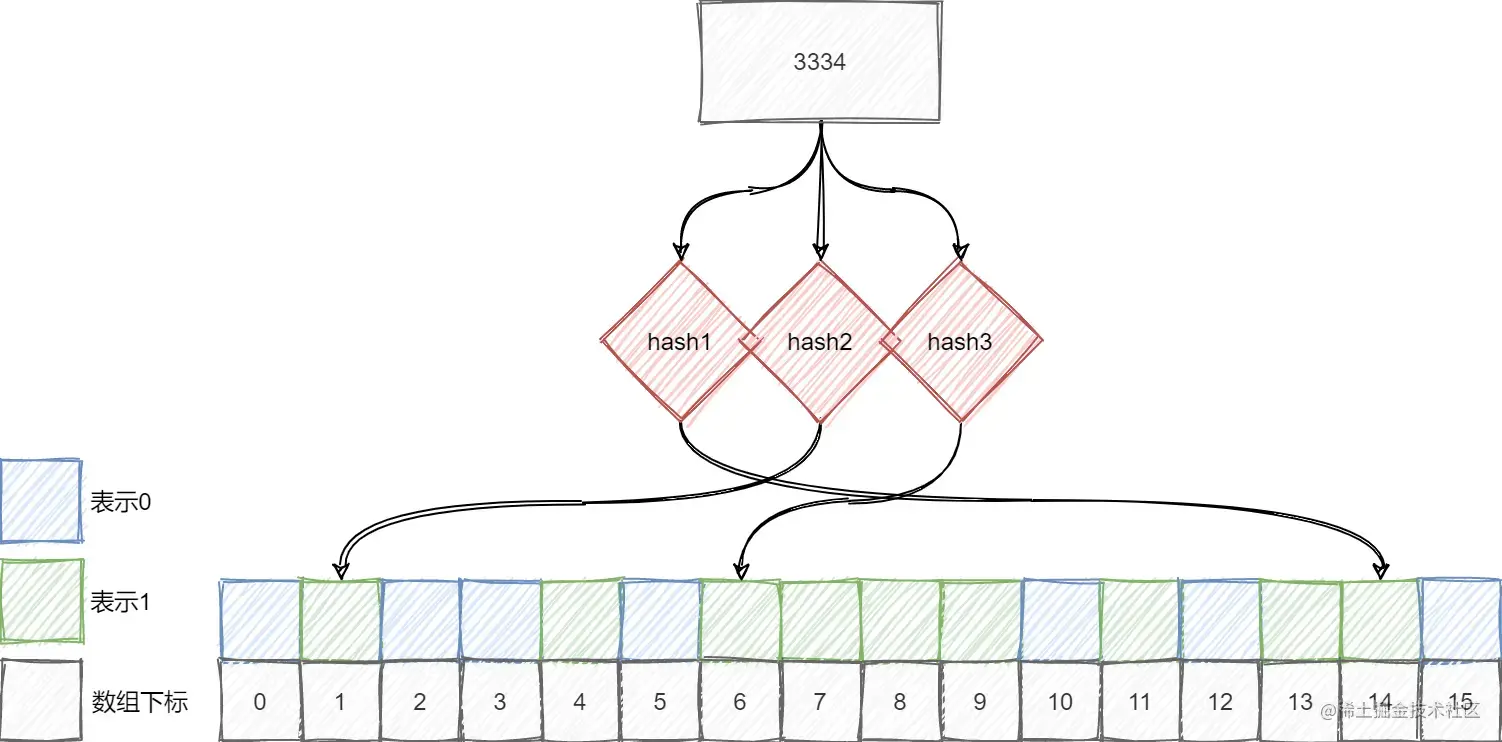
假设上图元素3334并没有加入集合,但是由于它映射的位置已经被其他元素所映射,则查询时会误判。
哈希函数
布隆过滤器里面的哈希函数需要是彼此独立且均匀分布(类似于哈希表的哈希函数),而且需要尽可能的快,比如murmur3就是一个很好的选择。
布隆过滤器的性能严重依赖于哈希函数的性能,而一般哈希函数的性能则依赖于输入串(一般为字节数组)的长度,因此为了提高布隆过滤器的性能建议减少输入串的长度。
下面是一个简单的性能测试,单位是字节,可以看到时间的消耗随着元素的增大基本是线性增长的:
cpu: Intel(R) Core(TM) i5-10210U CPU @ 1.60GHz BenchmarkAddAndContains/1-8 1805840 659.6 ns/op 1.52 MB/s 0 B/op 0 allocs/op BenchmarkAddAndContains/2-8 1824064 696.4 ns/op 2.87 MB/s 0 B/op 0 allocs/op BenchmarkAddAndContains/4-8 1819742 649.5 ns/op 6.16 MB/s 0 B/op 0 allocs/op BenchmarkAddAndContains/8-8 1828371 653.2 ns/op 12.25 MB/s 0 B/op 0 allocs/op BenchmarkAddAndContains/16-8 1828426 642.0 ns/op 24.92 MB/s 0 B/op 0 allocs/op BenchmarkAddAndContains/32-8 2106834 565.7 ns/op 56.57 MB/s 0 B/op 0 allocs/op BenchmarkAddAndContains/64-8 2063895 579.3 ns/op 110.48 MB/s 0 B/op 0 allocs/op BenchmarkAddAndContains/128-8 1767673 666.1 ns/op 192.17 MB/s 0 B/op 0 allocs/op BenchmarkAddAndContains/256-8 1292918 916.9 ns/op 279.21 MB/s 0 B/op 0 allocs/op BenchmarkAddAndContains/512-8 749666 1590 ns/op 322.11 MB/s 0 B/op 0 allocs/op BenchmarkAddAndContains/1024-8 388015 2933 ns/op 349.12 MB/s 0 B/op 0 allocs/op BenchmarkAddAndContains/2048-8 203404 5603 ns/op 365.51 MB/s 0 B/op 0 allocs/op BenchmarkAddAndContains/4096-8 105134 11303 ns/op 362.38 MB/s 0 B/op 0 allocs/op BenchmarkAddAndContains/8192-8 52305 22067 ns/op 371.23 MB/s 0 B/op 0 allocs/op
布隆过滤器大小、哈希函数数量、误判率
布隆过滤器的大小、哈希函数数量和误判率之间是互相影响的,如果我们想减少误判率,则需要更大的布隆过滤器和更多的哈希函数。但是我们很难直观地计算出这些参数,还好有两个公式可以帮助我们计算出准确的数值:
在我们可以确定我们的元素数量和能够容忍的错误率的情况下,我们可以根据下面公式计算布隆过滤器大小和哈希函数数量:
n = 元素数量 m = 布隆过滤器大小(位数) k = 哈希函数数量 fpr = 错误率(falsePositiveRate,假阳性率) m = n*(-ln(fpr)/(ln2*ln2)) k = ln2 * m / n
应用场景
数据库
布隆过滤器可以提前过滤所查询数据并不存在的请求,避免对磁盘访问的耗时。比如LevelDB就使用了布隆过滤器过滤请求github.com/google/leve… 。
黑名单
假设有10亿个黑名单URL,每个URL大小为64字节。使用Bloom Filter,如果错误率为0.1%,只需要1.4GB内存,如果错误率为0.0001%,也只需要2.9GB内存。
实现
这里简单的介绍一下Java的实现方式。
package com.jd.demo.test;
import java.util.Arrays;
import java.util.BitSet;
import java.util.concurrent.atomic.AtomicBoolean;
public class MyBloomFilter {
//你的布隆过滤器容量
private static final int DEFAULT_SIZE = 2 << 28;
//bit数组,用来存放结果
private static BitSet bitSet = new BitSet(DEFAULT_SIZE);
//后面hash函数会用到,用来生成不同的hash值,可随意设置,别问我为什么这么多8,图个吉利
private static final int[] ints = {1, 6, 16, 38, 58, 68};
//add方法,计算出key的hash值,并将对应下标置为true
public void add(Object key) {
Arrays.stream(ints).forEach(i -> bitSet.set(hash(key, i)));
}
//判断key是否存在,true不一定说明key存在,但是false一定说明不存在
public boolean isContain(Object key) {
boolean result = true;
for (int i : ints) {
//短路与,只要有一个bit位为false,则返回false
result = result && bitSet.get(hash(key, i));
}
return result;
}
//hash函数,借鉴了hashmap的扰动算法
private int hash(Object key, int i) {
int h;
return key == null ? 0 : (i * (DEFAULT_SIZE - 1) & ((h = key.hashCode()) ^ (h >>> 16)));
}
}
测试:
public static void main(String[] args) {
MyNewBloomFilter myNewBloomFilter = new MyNewBloomFilter();
myNewBloomFilter.add("张学友");
myNewBloomFilter.add("郭德纲");
myNewBloomFilter.add(666);
System.out.println(myNewBloomFilter.isContain("张学友"));//true
System.out.println(myNewBloomFilter.isContain("张学友 "));//false
System.out.println(myNewBloomFilter.isContain("张学友1"));//false
System.out.println(myNewBloomFilter.isContain("郭德纲"));//true
System.out.println(myNewBloomFilter.isContain(666));//true
System.out.println(myNewBloomFilter.isContain(888));//false
}
Guava实现:
pom.xml
<dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>25.1-jre</version> </dependency>
判断一个元素是否在集合中
public class Test1 {
private static int size = 1000000;
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size);
public static void main(String[] args) {
for (int i = 0; i < size; i++) {
bloomFilter.put(i);
}
long startTime = System.nanoTime(); // 获取开始时间
//判断这一百万个数中是否包含29999这个数
if (bloomFilter.mightContain(29999)) {
System.out.println("命中了");
}
long endTime = System.nanoTime(); // 获取结束时间
System.out.println("程序运行时间: " + (endTime - startTime) + "纳秒");
}
}
运行结果如下:
命中了 程序运行时间: 441616纳秒
自定义错误率
public class Test3 {
private static int size = 1000000;
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size, 0.01);
public static void main(String[] args) {
for (int i = 0; i < size; i++) {
bloomFilter.put(i);
}
List<Integer> list = new ArrayList<Integer>(1000);
// 故意取10000个不在过滤器里的值,看看有多少个会被认为在过滤器里
for (int i = size + 10000; i < size + 20000; i++) {
if (bloomFilter.mightContain(i)) {
list.add(i);
}
}
System.out.println("误判的数量:" + list.size());
}
}
运行结果如下:
误判的数量:941
对于缓存宕机的场景,使用白名单或者布隆过滤器都有可能会造成一定程度的误判。原因是除了Bloom Filter 本身有误判率,宕机之前的缓存不一定能覆盖到所有DB中的数据,当宕机后用户请求了一个以前从未请求的数据,这个时候就会产生误判。当然,缓存宕机时使用白名单/布隆过滤器作为应急的方式,这种情况应该也是可以忍受的。

文章评论