MySQL中搜索我们一般是使用like关键词来搜索,不过我们还可能遇更加复杂的搜索条件,例如需要正则表达式(写过程序的一般都知道)去寻找的情况,
匹配字符串
匹配字符串是正则表达式最基础的应用。我们先给出一个例子:我们从一个用户表中查询出名字中包含有100数字的用户
SELECT * FROM my_user WHERE `name` REGEXP '100';

我们得到了用户ID为1的用户:小红100
该语句中不同于之前的语句,我们使用REGEXP关键字代表后面为正则表达式
这条语句看起来和LIKE语句特别相似,而且也是可以使用LIKE语句来实现。那使用正则表达式的意义何在?
原因很简单。假设,我现在需要匹配不仅仅是包含100数字的用户,而是100,200,或者300,只要是整百的都需要匹配。或者说,我需要所有名字里面包含数字的,无论什么数字。那么使用LIKE来实现就会显得十分的困难。而正则表达式就会显得十分简单。
SELECT * FROM my_user WHERE `name` REGEXP '.00'; -- 匹配包含整百的名字,如100,200,300等等
表达式.00里面的点,代表的任意字符。也就是无论是1还是2还是9,或者是字母什么的都可以匹配,匹配任意。

SELECT * FROM my_user WHERE `name` REGEXP '[0-9]'; -- 匹配所有名字里面包含数字的用户
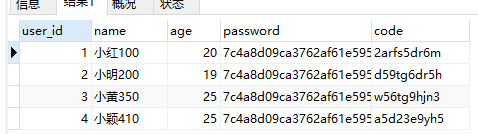
是不是来的比LIKE简单得多?上面的表达式,我们在接下来就会详细阐述。
正则和模糊查询的区别
那么我们什么情况下应该使用LIKE?什么情况下又适合使用正则表达式查询?
这里我们只需要记住LIKE查询和正则查询非常重要的差别即可。
先看两个例子:
1、之前的一条语句
SELECT * FROM my_user WHERE `name` REGEXP '100';

2、LIKE查询的实现
SELECT * FROM my_user WHERE `name` LIKE '100';

这里我们可以清楚的看到两者的区别:正则表达式返回了一条记录,而LIKE查询没有匹配到任何记录
结论:LIKE查询匹配整个列,如果需要匹配的字符串(比如上面的100)包含在列中,那么则无法匹配成功。而正则匹配则可以匹配列值内部的值,简单来说就是它会从第一个字符开始往后匹配,只要匹配有一个成功那么就会返回记录。这是两者重要的区别。
那么正则匹配是否也可以匹配整个字符,当然可以。不过需要涉及到另外的知识:定位符^和$,下面将会作详细解释。
使用或查询
如果正则表达式仅仅就是和LIKE有那么一点儿的差别,也就不会有这么高的地位了。下面才是显示身手的时候。
或查询也叫OR查询,是条件并列查询的一种情况。类似于编程语言里面的if else只要有一个条件符合就会被匹配。
SELECT * FROM my_user WHERE `name` REGEXP '100|200';
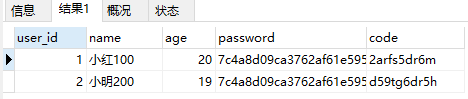
上面的语句查询了名字中包含了100或者200数字的用户,就是说两个数值只要匹配一个就可以返回数据。
当然你也可以给出多个或情况,他们之间使用竖线分割即可。比如:100|200|300|400
使用或查询的情况,有点儿类似于SELECT中使用OR条件连接的情况,你可以把它们想象成并入了一个正则表达式。
匹配多个字符之一
正则匹配中有一种特殊的OR匹配。
SELECT * FROM my_user WHERE `name` REGEXP '[12]';

上面表达式中我们使用了一个特殊的字符串[12],这个字符串的含义是:查询名字中包含有数字1或者数字2的记录,它是[1|2]的缩写。
这种,使用方括号将字符串括起来的写法,无论方括号内有多少字符串,其表达的含义都是匹配其中任意一个。
如果是[123456789]那么就代表,匹配名字中包含1或2或3或4或5或6或7或8或9的任何一个记录。
当然,字符串还可以查询被否定的情况。[^12]如果在12之前加上一个^符号,那么就代表除了1或2外的字符串。
SELECT * FROM my_user WHERE `name` REGEXP '[^12]';
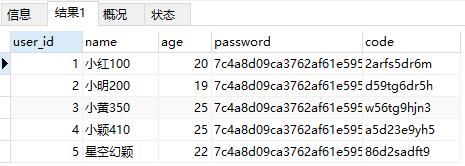
说明:表中小红100,虽然包含1,但是他包含了0。0不属于1或者2,所以被匹配。
匹配一个范围
看下我们上面有个集合[123456789],如果每次我们写正则时候都这么写,那么岂不是很麻烦。所以,我们可以简化这种情况,使用一个范围[1-9]来代替这串字符串。如果是匹配所有数字,那么就会包含0,我们可以使用[0-9]来表示。
SELECT * FROM my_user WHERE `name` REGEXP '[0-9]';
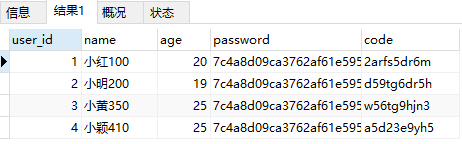
这个表达式将会匹配出所有名字中包含数字的记录。拆开理解就是,包含0或者1或者2...或者8或者9的记录。
而且,这里的范围不仅仅只能是数字,还可以是字母。比如[a-z]就是表示从字母a到字母z的所有数字,26个字母。小写完了,还有大写[A-Z]。那么我们将其组合起来[0-9a-zA-Z]这个表达式就十分强大了,可以表示包含数字,小写字母,大写字母的所有记录。
SELECT * FROM my_user WHERE `name` REGEXP '[0-9a-zA-Z]';
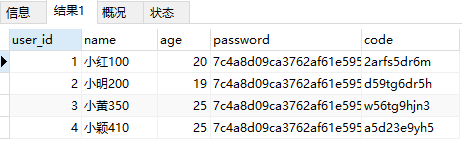
由于我名字里面没有包含字母的,所以结果和上面[0-9]相同。
匹配特殊字符串
我们来看下下面的一条语句:
SELECT * FROM my_user WHERE `name` REGEXP '[0-9]';
这个语句的意思是匹配名称包含所有数字的记录。0-9被方括号扩了起来,那么假设我现在就需要匹配方阔号该如何处理?
这个时候就需要用到匹配特殊字符的知识。为了匹配这些特殊的字符,我们需要使用转义功能,就是使用(双反斜杠)作为前导。假设我们需要匹配常用特殊字符即可这么写:
\\[ 匹配左方括号
\\. 匹配点号
\\] 匹配右方括号
\\| 匹配竖线
\\\ 匹配反斜杠自己本身
依次类推,其他特殊的字符串也可以使用这么方式处理。
双反斜杠加上一些字母还可以表示特殊的含义。
比如:
\\f 换页
\\n 换行
\\r 回车
\\t 制表符
\\v 纵向制表符
在一般的编程语言中,转义一般使用一个反斜线,在Mysql中为什么是两个才行?原因是:Mysql自己需要一个来识别,然后Mysql会将扣除了一个反斜杠的剩余的部分完全的交给正则表达式库解释,所以加起来就是两个了。
使用预定义字符集
虽然正则表达式提供了一些很长表示方式的缩写,比如[0-9]表示数字。[a-z]表示小写字母。但是,有些时候还是觉得复杂。所以,正则表达式还提供了一些预定义的字符类来方便我们开发。
简单来说,就像车牌使用苏代表江苏,而沪代表上海一样。
我们直接给出表直接参阅。
| 类 | 说明 |
|---|---|
| [:alnum:] | 任意数字和字母。相当于[a-zA-Z0-9] |
| [:alpha:] | 任意字符。相当于[a-zA-z] |
| [:blank:] | 空格和制表。相当于[(双斜杠,segmentfault这里双斜杠打不出来)t] |
| [:cntrl:] | ASCII控制字符(ASCII 0 到31和127) |
| [:digit:] | 任意数字。相当于[0-9] |
| [:graph:] | 与[:print:]相同,但是不包含空格 |
| [:lower:] | 任意的小写字母。相当于[a-z] |
| [:print:] | 任意可打印字符 |
| [:punct:] | 既不在[:alnum:]又不在[:cntrl:]中的任意字符 |
| [:space:] | 包括空格在内的任意空白字符。 |
| [:upper:] | 任意大写字母。相当于[A-Z] |
| [:xdigit:] | 任意十六进制的数字。相当于[a-fA-F0-9] |
元字符
之前匹配的内容都是单词匹配。就是如果匹配到一次就显示,匹配不到就不显示。但是,复杂的情况有时候要求匹配不止一次。假设我需要匹配名字中包含2-3位数字的记录。这个时候就需要使用一种特殊的元字符来修饰。
SELECT * FROM my_user WHERE `name` REGEXP '[0-9]{2,3}';

是不是非常简单?下面具体解释它的用法。
拿出这个特殊字符串[0-9]{2,3},除去前面的[0-9]后面的{2,3}就被成为重复元字符,它的作用就是使得前面的数字重复一定的次数。
| 元字符 | 作用 |
|---|---|
| * | 重复0次或者多次 |
| + | 重复一次或者多次。相当于{1,} |
| ? | 重复0次或者1次 |
| {n} | 重复n次 |
| {n,} | 重复至少n次 |
| {n,m} | 重复n-m次 |
SELECT * FROM my_user WHERE `name` REGEXP '[0-9]*'; -- 匹配名字包含或者不包含数字的记录
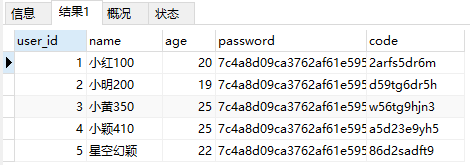
SELECT * FROM my_user WHERE `name` REGEXP '[0-9]{2,3}'; -- 匹配名字内包含2位数或者3位数的记录
定位元字符
除了之前的重复元字符,正则还有一种特殊的定位元字符
| 元字符 | 作用 |
|---|---|
| ^ | 文本开始 |
| $ | 文本结尾 |
| [[:<:]] | 词的开始 |
| [[:>:]] | 词的结尾 |
还记得之前区别LIKE和正则表达式的例子么?LIKE是对整个字符串进行匹配,而正则是匹配到就可以。
如果现在我们需要在邮箱+手机号码混合注册的账号中,挑选出手机号码,那么我们就要对账号进行从头到尾的匹配。
比如手机号码是11位数字,也就是说a11111111111不行,但是他又具备11个数字条件。
所以我们要求从头开始匹配到结尾,是11位数字。
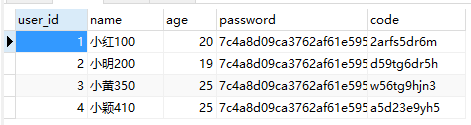
SELECT * FROM my_user WHERE `name` REGEXP '^[0-9]{11}$';
为了匹配到内容,我在数据库内又加了一条记录。
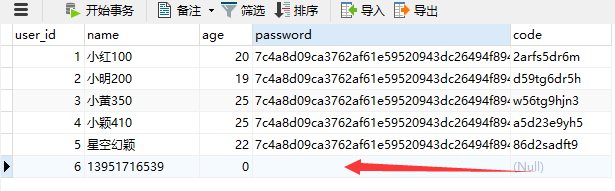
匹配结果
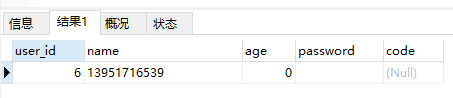
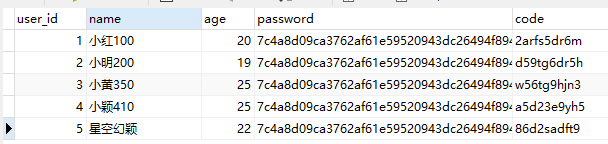
附录:用户表
SET FOREIGN_KEY_CHECKS=0;
-- ----------------------------
-- Table structure for my_user
-- ----------------------------
DROP TABLE IF EXISTS `my_user`;
CREATE TABLE `my_user` (
`user_id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(30) NOT NULL,
`age` tinyint(2) NOT NULL DEFAULT '0',
`password` varchar(40) NOT NULL,
`code` varchar(10) DEFAULT NULL,
PRIMARY KEY (`user_id`)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of my_user
-- ----------------------------
INSERT INTO `my_user` VALUES ('1', '小红100', '20', '7c4a8d09ca3762af61e59520943dc26494f8941b', '2arfs5dr6m');
INSERT INTO `my_user` VALUES ('2', '小明200', '19', '7c4a8d09ca3762af61e59520943dc26494f8941b', 'd59tg6dr5h');
INSERT INTO `my_user` VALUES ('3', '小黄350', '25', '7c4a8d09ca3762af61e59520943dc26494f8941b', 'w56tg9hjn3');
INSERT INTO `my_user` VALUES ('4', '小颖410', '25', '7c4a8d09ca3762af61e59520943dc26494f8941b', 'a5d23e9yh5');
INSERT INTO `my_user` VALUES ('5', '星空幻颖', '22', '7c4a8d09ca3762af61e59520943dc26494f8941b', '86d2sadft9');
中文示例
发现如果正则中有中文,需要把中文括号括起来,例如:
搜索符合这样:XX级XX班XX小组
SELECT * from t_table where name regexp '[:print:]+(级)[:print:]+(班)[:print:]+(小组)$'

文章评论