Puppeteer 是 Headless Chrome 的 Node.js 封装。通过它可方便地对页面进行截图,或者保存成 PDF。
镜像的设置
因为其使用了 Chromium,其源在 Google 域上,最好设置一下 npm 从国内镜像安装,可解决无法安装的问题。
推荐在项目中放置 .npmrc 或 .yarnrc 文件来进行镜像的设置,这样设置只针对项目生效,不影响其他项目,同时其他人不用重复在本地设置。
这是一个整理好的 .npmrc 文件,如果使用的是 yarn,对应的 .yarnrc 文件。也可通过如下命令从 GitHub gist 下载到项目中,
# .npmrc $ npx pkgrc # .yarnc $ npx pkgrc yarn
截取页面
使用 page.screenshot() API 进行截图的示例:
const puppeteer = require("puppeteer");
puppeteer.launch().then(async browser => {
const page = await browser.newPage();
await page.goto("https://example.com");
await page.screenshot({ path: "screenshot.png" });
await browser.close();
});
实际应用中,你需要加上等待时间,以保证页面已经完全加载,否则截取出来的画面是页面半成品的样子。
通过 page.waitFor() 可让页面等待指定时间,
const puppeteer = require('puppeteer');
puppeteer.launch().then(async browser => {
const page = await browser.newPage();
await page.goto('https://example.com');
// 等待一秒钟
+ await page.waitFor(1000);
await page.screenshot({path: 'screenshot.png'});
await browser.close();
});
但这里无论你指定的时长是多少,都是比较主观的值。页面实际加载情况受很多因素影响,机器性能,网络好坏等。即页面加载完成是个无法预期的时长,所以这种方式不靠谱。我们应该使用另一个更加有保障的方式,在调用 page.goto() 时,可指定 waitUntil 参数。
const puppeteer = require('puppeteer');
puppeteer.launch().then(async browser => {
const page = await browser.newPage();
await page.goto('https://example.com’,{
+ waitUtil: 'networkidle2'
});
await page.screenshot({path: 'screenshot.png'});
await browser.close();
});
networkidle2 - consider navigation to be finished when there are no more than 2 network connections for at least 500 ms.
-- 来自 puppeteer 文档中关于waitUtil参数的描述
networkidle2 会一直等待,直到页面加载后同时没有存在 2 个以上的资源请求,这个种状态持续至少 500 ms。
此时再进行截图,是比较保险的了。
截图时还有个实用的参数 fullPage,一般情况下也会搭配着使用,对整个页面进行截取。如果页面过长,超出了当前视窗(viewport),它会自动截取超出的部分,即截取结果是长图。这应该是大部分情况下所期望的。
await page.screenshot({ path: "screenshot.png", fullPage: true });
注意,其与 clip 参数互斥,即,如果手动指定了 clip 参数对页面进行范围的限定,则不能再指定 fullPage 参数。
// ? 抛错!
await page.screenshot({
path: "screenshot.png",
fullPage: true,
clip: {
x: 0,
y: 0,
width: 400,
height: 400
}
});
针对页面中某个元素进行截取
如果你使用过 Chrome DevTool 中的截图命令,或许知道,其中有一个针对元素进行截取的命令。
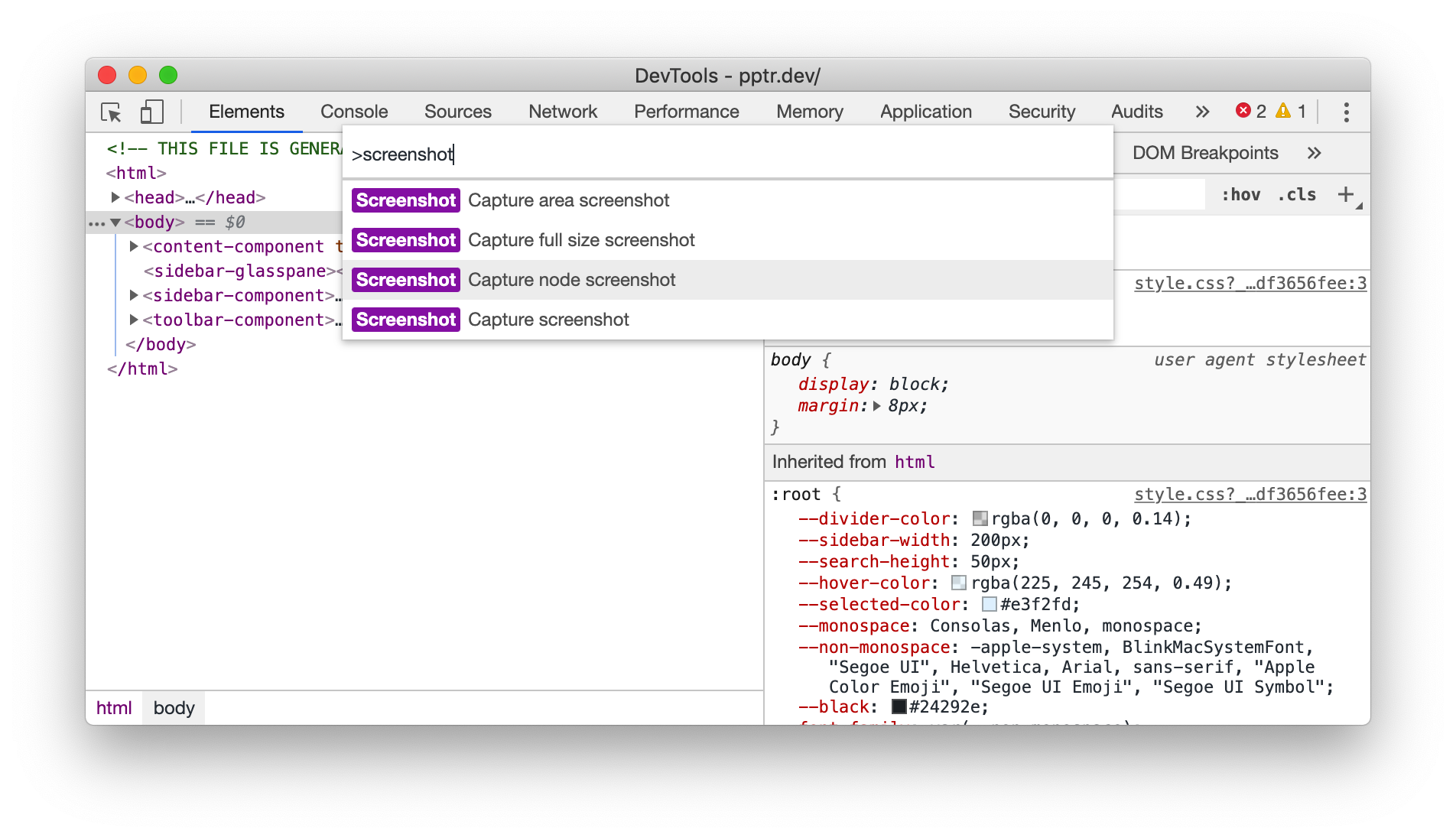
Chrome DevTool 中对元素进行截图的命令
所以,除了对整个页面进行截取,Chrome 还支持对页面某个元素进行截取。通过 elementHandle .screenshot() 可针对具体元素进行截取。
这就很实用了,能够满足大部分自定义的需求。大多数情况下,我们只对 body 部分感兴趣,通过只对 body 进行截取,就不用指定长宽而且自动排除掉 body 外多余的留白等。
const puppeteer = require("puppeteer");
puppeteer.launch().then(async browser => {
const page = await browser.newPage();
await page.goto("https://example.com", {
waitUtil: "networkidle2"
});
const element = await page.$("body");
await element.screenshot({
path: "screenshot.png"
});
});
其参数与 page.screenshot() 一样。需要注意的是,虽说一样,但其中是不能使用 fullPage 参数的。因为针对元素进行图片截取已经表明是局部截图了,与 fullPage 截取整个页面是冲突的,但它还是会自动滚动以截取完整的这个元素, fullPage 的优点没有丢掉。
数据的返回
生成的图片可直接返回,也可保存成文件后返回文件地址。
其中,截图方法 page.screenshot([options]) 的返回是 <Promise<string|Buffer>>,即生成的可能是 buffer 数据,也可以是base64 形式的字符串数据,默认为 Buffer 内容,通过设置 encoding 参数为 base64 便可得到字符串形式的截图数据。
以 Koa 为例,binary 形式的 buffer 数据直接赋值给 ctx.body 进行返回,通过 response.attachment 可设置返回的文件名。
app.use(async ctx => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(url);
const buffer = await page.screenshot();
await browser.close();
ctx.response.attachment("screenshot.png");
ctx.body = buffer;
});
字符串形式时,需要注意拿到的并不是标准的图片 base64 格式,它只包含了数据部分,并没有文件类型部分,即 data:image/png;base64,所以需要手动拼接后才是正确可展示的图片。
app.use(async ctx => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(url);
const base64 = await page.screenshot({ encoding: "base64" });
await browser.close();
ctx.body = `<img src="data:image/png;base64,${base64}"/>`;
});
如果你是以异步接口形式返回到前端,只需要将 "data:image/png;base64,${base64}" 这部分作为数据返回即可。
当然,字符串形式下,仍然是可以返回成文件下载的形式的,
app.use(async ctx => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(url);
const base64 = await page.screenshot({ encoding: "base64" });
await browser.close();
ctx.response.attachment("screenshot.png");
const image = new Buffer(base64, "base64");
ctx.body = image;
});
PDF 的生成
通过 page.pdf([options]) 可将页面截取成 PDF 格式。
const puppeteer = require("puppeteer");
async function run() {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.emulateMedia("screen");
await page.goto("https://www.google.com/chromebook/");
await page.pdf({
path: "puppeteer.pdf",
format: "A4"
});
await browser.close();
}
run();
一般 PDF 用于打印,所以默认以 print 媒体查询 (media query)的样式来截取。这里调用 page.emulateMedia("screen") 显式指定环境为 screen 而不是 print 是为了得到更加接近于页面在浏览器中展示的效果。
需要注意的是,如果页面中使用了背景图片,上面代码截取出来是看不到的。
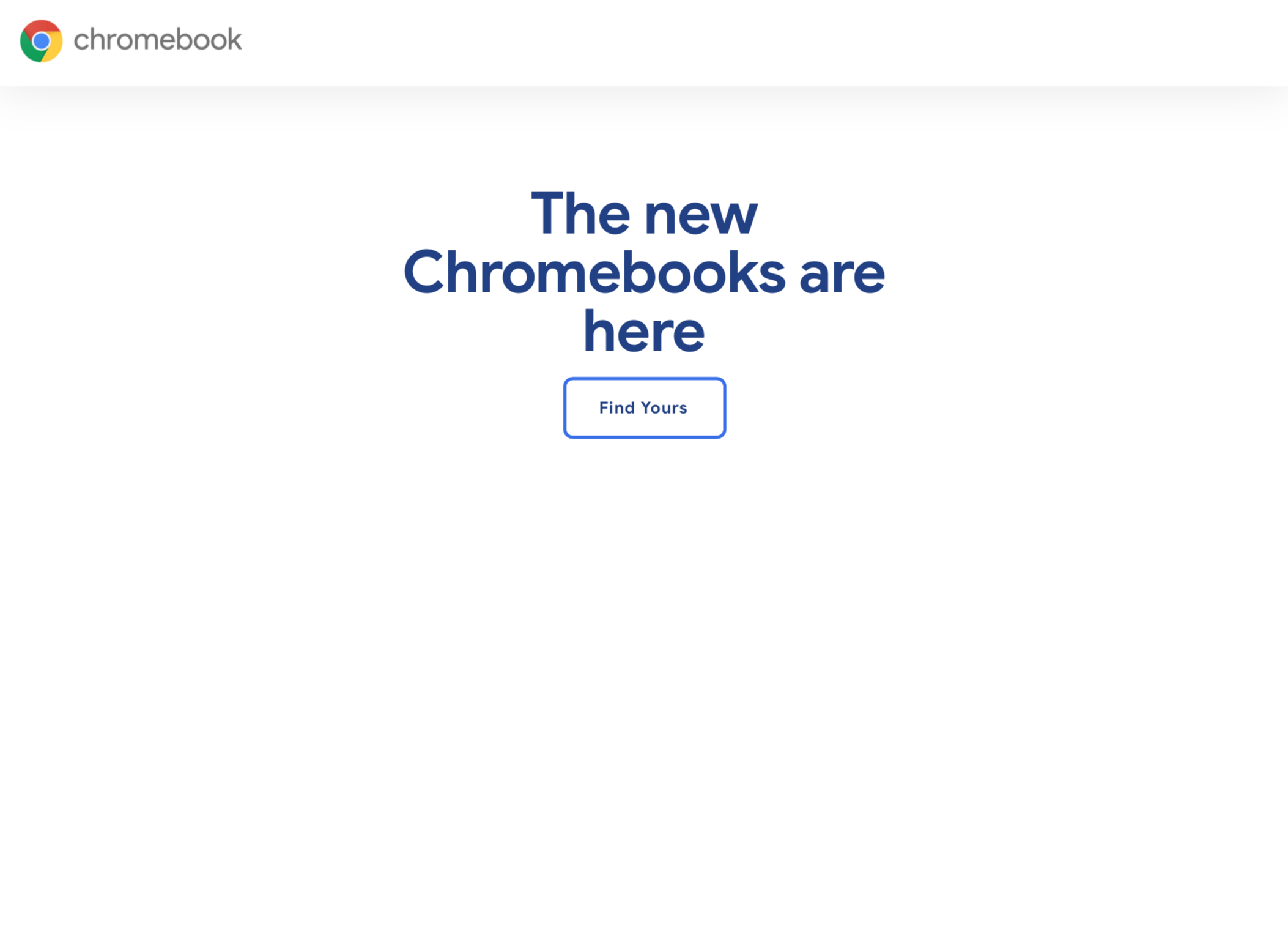
需要设置截取时的 printBackground 参数为 true:
await page.pdf({
path: "puppeteer.pdf",
format: "A4",
+ printBackground: true
});
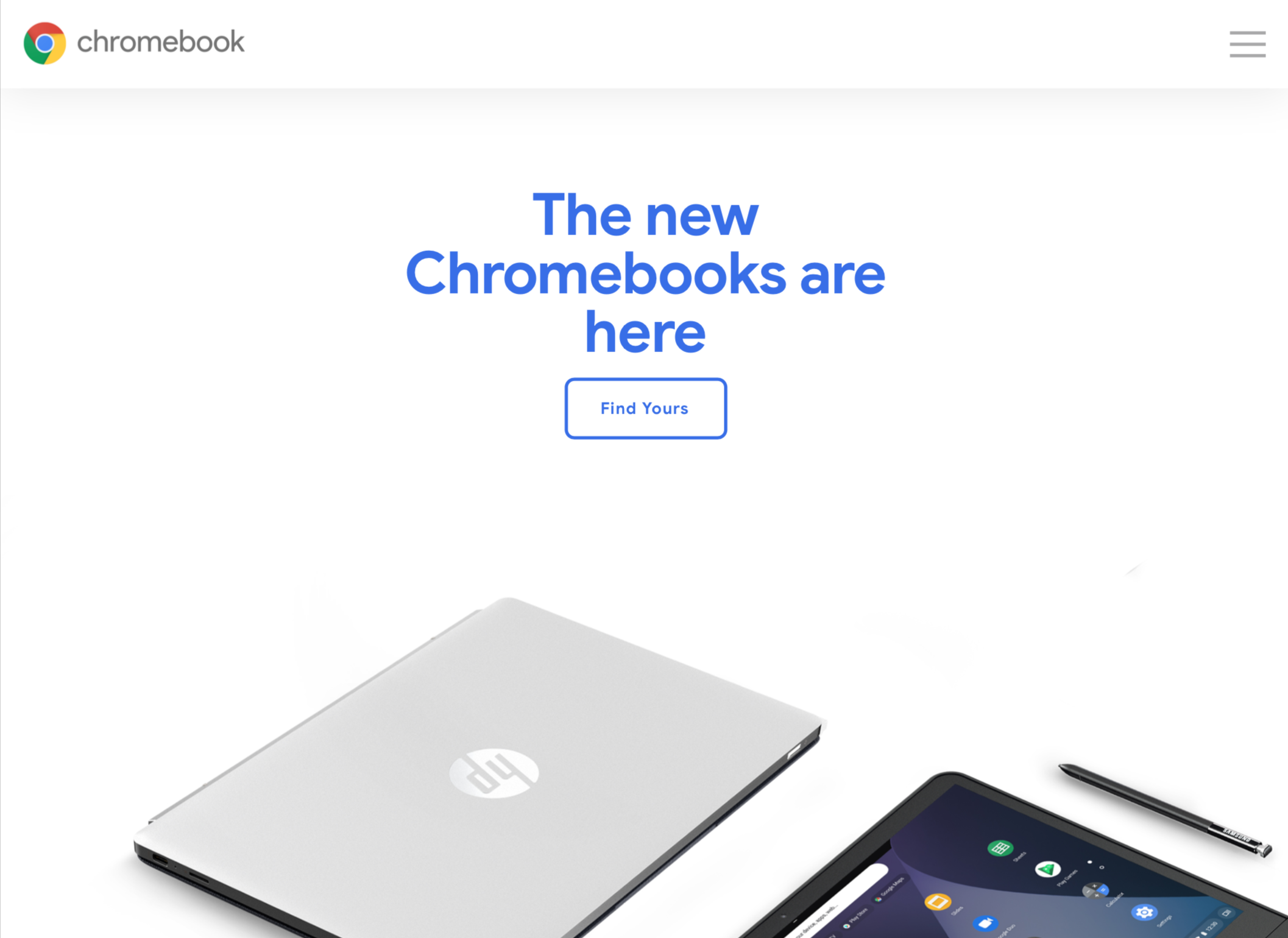
修正后截图的 PDF 背景图片正常显示
一些问题
服务器字体文件问题
部署到全新的 Linux 环境时,大概率你会看到截来的图片中中文无法显示。
中文字体缺失的情况
那是因为系统缺少中文字体,Chromium 无法正常渲染。你需要安装中文字体,通过包管理工具或者手动下载安装。
$ sudo apt-get install language-pack-zh* $ sudo apt-get install chinese*
Docker上出现中文字体乱码问题,请参考: https://blog.terrynow.com/2022/10/29/use-node-puppeteer-docker-mingalevme-screenshoter-as-service-to-fullscreen-screenshot-and-support-chinese/
服务器上 Chromium 无法启动的问题
在 Puppeteer 的 troubleshoting 文档 中有对应的解决方案。
(node:24206) UnhandledPromiseRejectionWarning: Error: Failed to launch chrome!
一般是机器上缺少对应的依赖库,安装补上即可。Puppeteer 自带的 Chromium 是非常纯粹的,它不会安装除了自身作为浏览器外的其他东西。
通过 ldd (List Dynamic Dependencies)命令可查看运行 Chromium 运行所需但缺少的 shared object dependencies。
查看缺少的依赖项
那么多,一个个搜索(因为这里例出的名称不一定就是直接可用来安装的名称)安装多麻烦。所以需要用其他方法。
以 Debian 系统为例。
tips: 可通过 $ cat /etc/os-release 查看系统信息从而判断是什么系统。
$ cat /etc/os-release PRETTY_NAME="Debian GNU/Linux 9 (stretch)" NAME="Debian GNU/Linux" VERSION_ID="9" VERSION="9 (stretch)" ID=debian HOME_URL="https://www.debian.org/" SUPPORT_URL="https://www.debian.org/support" BUG_REPORT_URL="https://bugs.debian.org/"
脚本安装
通过 troubleshoting 页面 Chrome headless doesn't launch 部分其列出的对应系统所需依赖中,将所有依赖复制出来组装成如下的命令执行:
sudo apt-get install gconf-service libasound2 libatk1.0-0 libatk-bridge2.0-0 libc6 libcairo2 libcups2 libdbus-1-3 libexpat1 libfontconfig1 libgcc1 libgconf-2-4 libgdk-pixbuf2.0-0 libglib2.0-0 libgtk-3-0 libnspr4 libpango-1.0-0 libpangocairo-1.0-0 libstdc++6 libx11-6 libx11-xcb1 libxcb1 libxcomposite1 libxcursor1 libxdamage1 libxext6 libxfixes3 libxi6 libxrandr2 libxrender1 libxss1 libxtst6 ca-certificates fonts-liberation libappindicator1 libnss3 lsb-release xdg-utils wget
通过安装 Chrome 来自动安装
直接安装一个非 Chromium 版本的 Chrome,它会把依赖自动安装上。
Chrome 是基于 Chromium 的发行版,包括 google-chrome-stable,google-chrome-unstable,google-chrome-beta,安装任意一个都行。
还是以 Debian 系统为例:
$ apt-get update && apt-get install google-chrome-unstable
如果直接执行上面的安装,会报错:
E: Unable to locate package google-chrome-unstable
这是安装程序时的一个安全相关策略 ,需要先设置一下 apt-key。
$ wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | sudo apt-key add -
然后设置 Chrome 的仓库:
$ sudo sh -c 'echo "deb [arch=amd64] http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google.list'
再次执行安装便正常进行了。
安装时可以看到会提示所需的依赖项:
安装 Chrome 时的提示信息
按[Y] 确认即可。
有了这些依赖,Puppeteer 中的 Chromium 便可运行了。
$ google-chrome-unstable --version Google Chrome 75.0.3745.4 dev $ ldd node_modules/puppeteer/.local-chromium/linux-641577/chrome-linux/chrome | grep not
google-chrome-unstable --version 正常输出版本号表示安装成功,再次检查 not found 的依赖项输出为空。
我们的目的只是安装依赖,所以装完后可移除 Chome。apt-get remove google-chrome-unstable 时会自动列出其依赖项,就像安装时一样。后续如果机器上不再需要 Chromium 了可通过 apt-get autoremove 来清理。
卸载 Chrome 时的提示信息
sandbox 的问题
Linux 上 Puppeteer 启动 Chromium 时可能会看到如下的错误提示:
[0402/152925.182431:ERROR:zygote_host_impl_linux.cc(89)] Running as root without --no-sandbox is not supported. See https://crbug.com/638180.
错误信息已经很明显,所以在启动时加上 --no-sandbox 参数即可。
const browser = await puppeteer.launch({ args: ["--no-sandbox"] });
但考虑到安全问题,Puppeteer 是强烈不建议在无沙盒环境下运行,除非加载的页面其内容是绝对可信的。
如果需要设置在沙盒中运行,可参考文档中的两种方法。

文章评论