Redis是一个非常流行的key-value存储系统,而作为其官方推荐的Java版客户端 Jedis也非常强大和稳定。
在单个客户端中,如果需要读写大量数据,可以考虑采用管道(Pipeline)方式。如果采用管道方式,那么多条命令可以通过批量的方式一次性地发送到服务器,而结果也会一次性返回到客户端。
本文将介绍Redis 使用管道(Pipeline)方式提升操作性能。
一、管道(Pipeline)
未使用管道方式执行N条命令,如图所示:
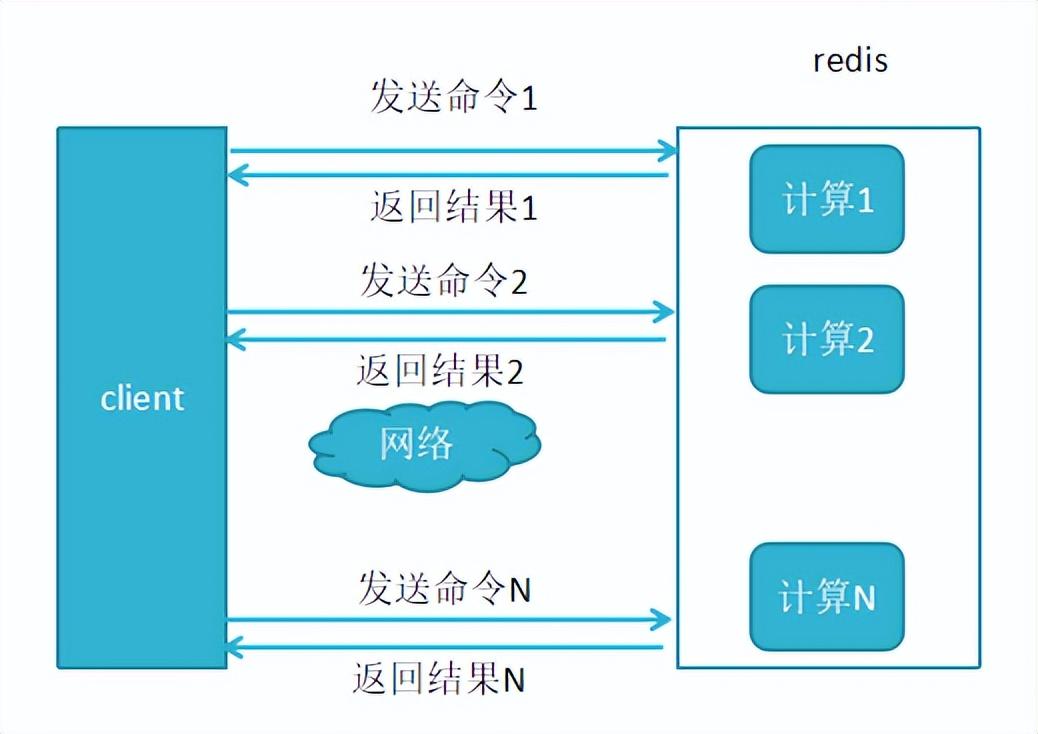
管道(Pipeline):一次向Redis发送多条命令。
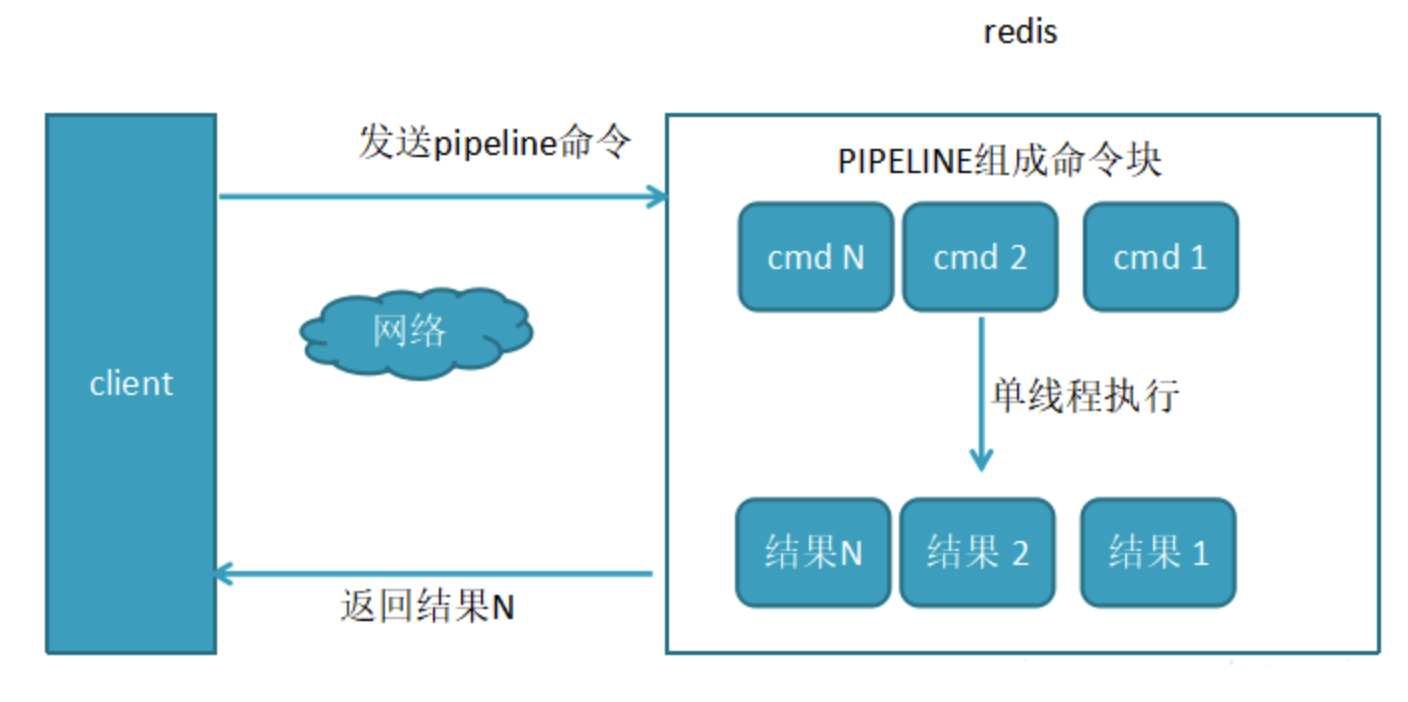
客户端可以一次性发送多个请求而不用等待服务器的响应,待所有命令都发送完后再一次性读取服务的响应,这样可以极大的降低多条命令执行的网络传输开销,管道执行多条命令的网络开销实际上只相当于一次命令执行的网络开销。
需要注意到是用Pipeline方式打包命令发送,Redis必须在处理完所有命令前先缓存起所有命令的处理结果。打包的命令越多,缓存消耗内存也越多。
所以并不是打包的命令越多越好。pipeline中发送的每个Command都会被Server立即执行,如果执行失败,将会在此后的响应中得到信息;也就是Pipeline并不是表达“所有Command都一起成功”的语义,管道中前面命令失败,后面命令不会有影响,继续执行。
二、管道执行示例代码
创建示例项目,测试一下管道执行的性能。
PipelineApp 示例代码如下所示:
public class PipelineApp {
public static void main(String[] args) {
Jedis jedis = new Jedis("localhost", 6379);
jedis.auth("123456");
// 开始时间
long startTime = System.currentTimeMillis();
for(int i = 0; i<10000; i++) {
jedis.set("key_" + i, String.valueOf(i));
jedis.get("key_" + i);
}
// 结束时间
long endTime = System.currentTimeMillis();
System.out.println("正常执行时间(ms):" + (endTime-startTime));
startTime = System.currentTimeMillis();
Pipeline pipeline = jedis.pipelined();
for (int i = 0; i < 10000; i++) {
pipeline.set("key_" + i, String.valueOf(i));
pipeline.get("key_" + i);
}
pipeline.sync();
endTime = System.currentTimeMillis();
System.out.println("管道执行时间(ms):" + (endTime-startTime));
}
}
启动应用,输出结果如下所示:
正常执行时间(ms):1802
管道执行时间(ms):78
可以看到以管道方式运行的耗时会远小于非管道方式运行的耗时,特别是客户端与服务端的网络延迟越大,性能体能越明显。所以,在项目中如果需要大批量向Redis 服务器读写数据,那么建议使用管道方式。
三、Pipeline正确使用方式
使用pipeline组装的命令个数不能太多,不然数据量过大,增加客户端的等待时间,还可能造成网络阻塞,可以将大量命令的拆分多个小的pipeline命令完成。
管道不会管所有的命令是否都执行成功,只是逐条地执行命令。管道不能保证原子性,不支持事务。可以使用lua脚本来实现原子性。

文章评论